Now, I promised you all something that would help make running SPM analyses easier; for although we would all like something that is both transparent and usable, in most FMRI packages they are polar of each other. SPM in many ways is very usable; but this tends to be more hindrance than asset when running large groups of subjects, when manually selecting each session and copying and pasting by hand become not only tedious, but dangerous, as the probability of human error is compounded with each step. Best to let the machines do the work for you when you can. Anything else is an affront to them; you'll wake more than just the dogs.
Do assist our future overlords in their work, command lines for each step should be used whenever possible. But, rummily enough, SPM offers little documentation about this, and it more or less needs to be puzzled out on your own. For most processing this wouldn't be too much of a hassle, but there is one step where it is indispensable, more indispensable, if possible, than Nutella on a banana sprinkled with chopped walnuts. Or possibly warm Nutella drizzled on top of vanilla ice cream and left standing until it cools and hardens into a shell. Has anyone tried this? Could you let me know how it tastes? Thanks!
Where was I? Right; the one step where you need batching is first-level analysis, where timing information is entered for each session (or run) for each subject. Back in the autumn of aught eight during my days as a lab technician I used to be just like you, arriving to work in the morning and easing my falstaffian bulk into my chair before starting my mind-numbing task of copying and pasting onset times into each condition for each run, invariably tiring of it after a few minutes but keeping at it, and maybe completing a few subjects by the end of the day. Not the most exciting or fulfilling work, and I probably screwed a lot of things up without noticing it.
SPM has tried to anticipate problems like this by specifying a Multiple Condition option through their interface, where you supply a .mat file for each session that contains all of the names, onsets, and durations for that session, and everything is automatically filled in for you. Which sounds great, until you realize that creating Matlab files is, like, hard, and then you go back to your old routine. (The manual also says that these .mat files can be generated automatically by presentation software such as COGENT, but I have never met anyone who has ever used COGENT; this is, in all likelihood, a fatcat move by Big Science to get you to buy a piece of software that you don't need.)
What we will be doing, then, is trying to make this as straightforward and simple of a process as possible. However, this assumes that you have your onsets organized in a certain way; and first we will talk about how to create those onsets from your stimulus presentation program. This will allow you much more flexibility, as you can choose what you want to write into a simple text file without having to go through copying and pasting data from the E-Prime DataAid program into Excel for further processing. (I use E-Prime, and will be reviewing that here, but I believe that most presentation programs will allow you to write out data on the fly.)
Within E-Prime, you will need to know exactly when the scanner started, and use this as time zero for your onsets files. I usually do this by having a screen that says "Waiting for scanner..." which only terminates once the scanner sends a trigger pulse through a USB cord hooked up to the presentation laptop. We have a Siemens Trio scanner, which sends a backtick ( ` ); check whether your scanner does the same.
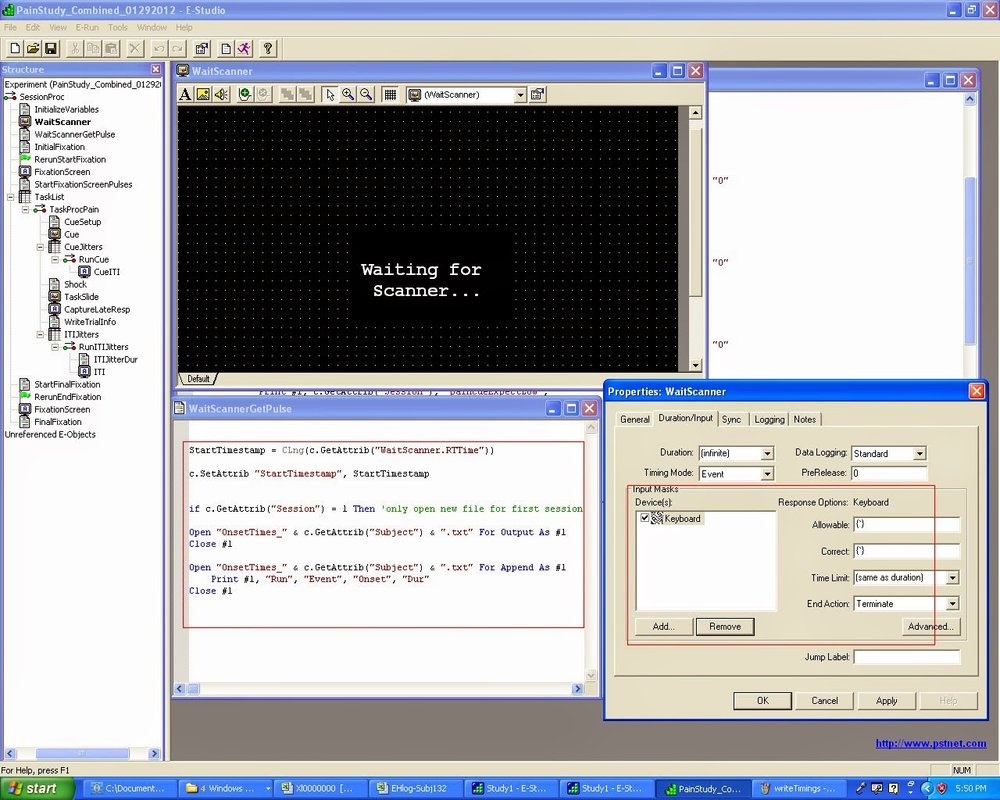
Note that I have an inline script (i.e., an object that contains E-Basic code) right after the WaitScanner slide that contains the following code:
StartTimestamp = CLng(c.GetAttrib("WaitScanner.RTTime")
c.SetAttrib "StartTimestamp", StartTimestamp
if c.GetAttrib("Session") = 1 Then
Open "OnsetTimes_" & c.GetAttrib("Subject") & ".txt" For Output as #1
Close #1
Open "OnsetTimes_" & c.GetAttrib("Subject") & ".txt" For Append As #1
Print #1, "Run", "Event", "Onset", "Dur"
Close #1
end if
Also, in the duration/input tab for the properties of waitscanner, I have the Keyboard accepting ( ` ) as an input, and termination when it receives that backtick. The StartTimestamp will simply record when the scanner first started, and the if/then statement ensures that the file does not get overwritten when the next run is started.
After that, the StartTimestamp variable and the newly create text file can be used to record information after each event, with the specified condition being determined by you. To calculate the timing for each event, all you have to do is grab the onset time of a condition through the c.GetAttrib command, and subtract the StartTimestamp variable from that:

Additional runs will continue to append to the text file, until you have all of the timing information that you need for your subject. This can then be parsed by a script and divided into multiple condition .mat files, which we will discuss tomorrow.
Do assist our future overlords in their work, command lines for each step should be used whenever possible. But, rummily enough, SPM offers little documentation about this, and it more or less needs to be puzzled out on your own. For most processing this wouldn't be too much of a hassle, but there is one step where it is indispensable, more indispensable, if possible, than Nutella on a banana sprinkled with chopped walnuts. Or possibly warm Nutella drizzled on top of vanilla ice cream and left standing until it cools and hardens into a shell. Has anyone tried this? Could you let me know how it tastes? Thanks!
Where was I? Right; the one step where you need batching is first-level analysis, where timing information is entered for each session (or run) for each subject. Back in the autumn of aught eight during my days as a lab technician I used to be just like you, arriving to work in the morning and easing my falstaffian bulk into my chair before starting my mind-numbing task of copying and pasting onset times into each condition for each run, invariably tiring of it after a few minutes but keeping at it, and maybe completing a few subjects by the end of the day. Not the most exciting or fulfilling work, and I probably screwed a lot of things up without noticing it.
SPM has tried to anticipate problems like this by specifying a Multiple Condition option through their interface, where you supply a .mat file for each session that contains all of the names, onsets, and durations for that session, and everything is automatically filled in for you. Which sounds great, until you realize that creating Matlab files is, like, hard, and then you go back to your old routine. (The manual also says that these .mat files can be generated automatically by presentation software such as COGENT, but I have never met anyone who has ever used COGENT; this is, in all likelihood, a fatcat move by Big Science to get you to buy a piece of software that you don't need.)
What we will be doing, then, is trying to make this as straightforward and simple of a process as possible. However, this assumes that you have your onsets organized in a certain way; and first we will talk about how to create those onsets from your stimulus presentation program. This will allow you much more flexibility, as you can choose what you want to write into a simple text file without having to go through copying and pasting data from the E-Prime DataAid program into Excel for further processing. (I use E-Prime, and will be reviewing that here, but I believe that most presentation programs will allow you to write out data on the fly.)
Within E-Prime, you will need to know exactly when the scanner started, and use this as time zero for your onsets files. I usually do this by having a screen that says "Waiting for scanner..." which only terminates once the scanner sends a trigger pulse through a USB cord hooked up to the presentation laptop. We have a Siemens Trio scanner, which sends a backtick ( ` ); check whether your scanner does the same.
Note that I have an inline script (i.e., an object that contains E-Basic code) right after the WaitScanner slide that contains the following code:
StartTimestamp = CLng(c.GetAttrib("WaitScanner.RTTime")
c.SetAttrib "StartTimestamp", StartTimestamp
if c.GetAttrib("Session") = 1 Then
Open "OnsetTimes_" & c.GetAttrib("Subject") & ".txt" For Output as #1
Close #1
Open "OnsetTimes_" & c.GetAttrib("Subject") & ".txt" For Append As #1
Print #1, "Run", "Event", "Onset", "Dur"
Close #1
end if
Also, in the duration/input tab for the properties of waitscanner, I have the Keyboard accepting ( ` ) as an input, and termination when it receives that backtick. The StartTimestamp will simply record when the scanner first started, and the if/then statement ensures that the file does not get overwritten when the next run is started.
After that, the StartTimestamp variable and the newly create text file can be used to record information after each event, with the specified condition being determined by you. To calculate the timing for each event, all you have to do is grab the onset time of a condition through the c.GetAttrib command, and subtract the StartTimestamp variable from that:
Additional runs will continue to append to the text file, until you have all of the timing information that you need for your subject. This can then be parsed by a script and divided into multiple condition .mat files, which we will discuss tomorrow.